Relationships are like CSVs—one wrong delimiter, and it all breaks.
CSV stands for Comma-Separated Values. It’s a plain text format that stores tables. Each line holds one record, and fields within a record are split by commas. Many programs use CSV files because they’re easy to create, read, and move between systems. To work with CSV data from the command line, especially for filtering and analyzing, csvkit is a useful tool. Down are easy commands for basic CSV file EDA:
Step 1: Install or upgrade csvkit (in windows 11)
pip install --upgrade csvkit
Step 2: Extract rows where the “Attack_type” column contains “Normal”
csvgrep -c "Attack_type" -r "Normal" data.csv > normal_rows.csv
Step 3: View structure and summary stats of the filtered file
csvstat ransomware_rows.csv
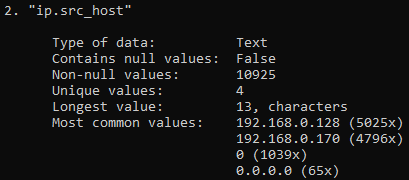
Step 4: Check for missing or summary stats in the “dns.qry.name.len” column (same as step 3 but here for specific column)
csvstat -c "dns.qry.name.len" normal_rows.csv
Step 5: See frequency distribution for “dns.qry.name.len”
csvcut -c "dns.qry.name.len" normal_rows.csv | csvstat --freq